Appearance
Execute
Workflows and Experiments
In EarthCODE, a published product is not just a dataset—it is the outcome of a defined process, captured as an Experiment. In addition to the definitions above, a product includes a reference to the experiment that produced it, making it possible to understand, reuse, and reproduce the results.

An Experiment describes everything needed to generate a product. This includes:
- A human-readable description of the experiment’s purpose and context
- A machine-executable workflow used to transform inputs into outputs
- A definition of the input data used, including references to other published products
- A configuration describing any parameters or settings used during execution
These components ensure that published results are reproducible. They are defined using structured metadata and described using STAC and Record Items, which together provide the semantic and technical context needed for discovery and reuse.
A workflow defines the set of processing steps used in an experiment. It is not just source code—it is something that can be formally executed within a platform using a defined interface. Workflows may take different forms, including:
- openEO Process Graphs
- OGC API Processes (e.g. CWL, Application Package)
- MLflow models
- Jupyter Notebooks
The source code that supports a workflow may be referenced, but the workflow itself must be described in a way that allows it to be executed by integrated EarthCODE platforms. This distinction enables reproducibility and compatibility across platforms. Platforms handle these definitions.
Workflows are typically stored in the EarthCODE GitHub organization, and referenced in the EarthCODE Open Science Catalog as part of the workflow metadata.
Experiments also declare the input datasets used and a configuration that defines any parameters passed to the workflow at runtime. Inputs are referenced using unique identifiers, making it easier to validate and re-run experiments with the same data. Configuration values are usually a set of simple name–value pairs, but can vary depending on workflow complexity.
In summary, EarthCODE combines the concepts of workflows and products are combined. A product is the result of a successfully run experiment. The product metadata links back to the experiment metadata, which in turn references the workflow, input, and config. Together, this structure ensures reproducibility, FAIRness and Openness.

Executing Experiments
EarthCODE integrates compute capabilities through standard interfaces that support a variety of processing paradigms. Experiments can be executed as containerized application packages, data‑cube workflows, machine learning inference services or full model training runs—all discoverable and shareable under FAIR principles. Platforms are expected to provide an interface for requesting the execution of one or many of the following.
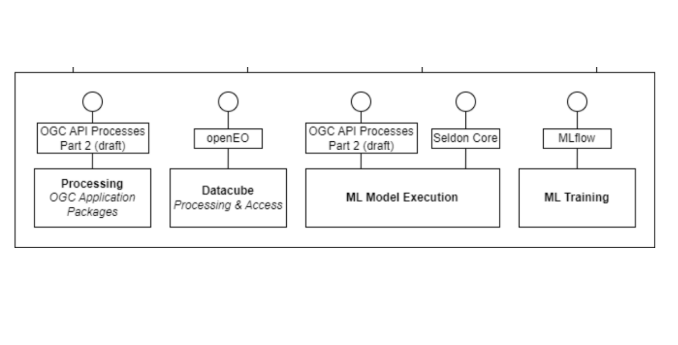
OGC Application Packages (Best Practice for EOAP) General purpose algorithms and workflows are delivered as OGC Application Packages. Each package bundles code, dependencies and a defined entry point, and can be deployed on any platform supporting OGC API – Processes.
openEO Processing Graphs (openEO API process graphs)
Data cube analytics leverage the openEO API, which accepts a processing graph describing operations on multidimensional datacubes. Platforms that implement the openEO specification execute these graphs close to the hosted data, enabling scalable, server‑side computation.
Machine Learning Model Execution
Inference workloads can be exposed via OGC API Processes or served through Seldon Core Seldon Core. Models packaged as reusable services respond to standardized process calls, allowing EarthCODE experiments to incorporate AI inference without bespoke integration effort.
Machine Learning Training
Model development and training runs are managed with (MLflow), which tracks experiments, parameters, metrics and artifacts. By invoking MLflow’s REST API within workflows, platforms provide end‑to‑end support for training, versioning and deployment of machine learning models.
To better understand what is expected for making submissions to the catalog, it helps to look at the following examples for Experiments and Products.
Examples of an Experiment Submission to the Open Science Catalog
https://opensciencedata.esa.int/workflows/worldcereal-workflow/record